

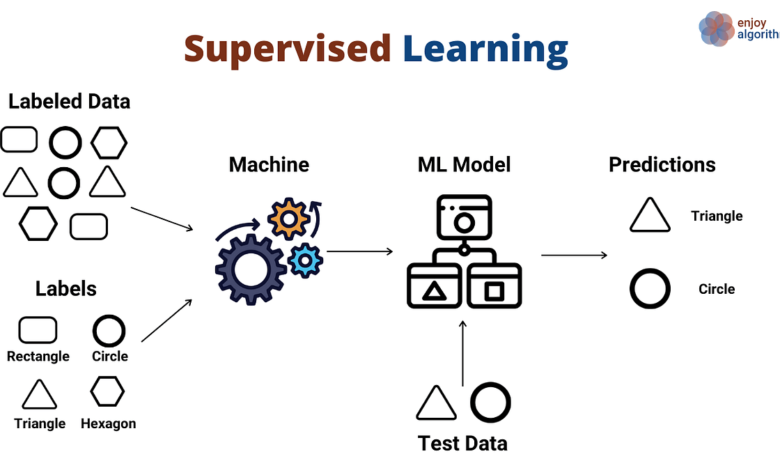
Supervised learning is a famous system in which a set of rules learns from categorized records to make predictions or classify new, unseen records factors. It entails schooling a version with enter-output pairs, in which the preferred output is thought for every entry. This article will offer a complete review of supervised gaining knowledge of its algorithms, challenges, and applications.
How Does Supervised Learning Work?
They are supervised, gaining knowledge of works by iteratively adjusting the version’s parameters to limit the distinction between anticipated and actual outputs. The rules measure the mistake or loss among expected and actual outputs and update the version primarily based on this error. The procedure keeps till the version achieves a preferred stage of accuracy.
Types of Supervised Learning Algorithms
There are numerous forms of supervised gaining knowledge of algorithms available. Let’s discover a number of the usually used ones:
Linear Regression
Linear regression is an easy but effective set of rules for predicting non-stop numerical values. It assumes a linear dating between the enter variables and the output variable.
Logistic Regression
Logistic regression is, in general, used for binary classification problems. It estimates the chance of an example belonging to a specific magnificence.
Decision Trees
Decision timber is a flexible algorithm that can handle each regression and class task. Partition the center area into areas and make predictions based on the bulk magnificence or the cost of the times inside every region.
Random Forest
A random wooded area is an ensemble gaining knowledge of a set of rules that mixes more than one choice timber to make predictions. It improves accuracy and decreases overfitting by aggregating the predictions of man or woman timber.
Support Vector Machines (SVM)
SVM is a practical set of rules for each class and regression task. It separates records factors in the usage of hyperplanes and maximizes the margin among classes.
Naive Bayes
Naive Bayes is a probabilistic set of rules that assumes independence among features. It is broadly used for textual content class and unsolicited mail filtering.
K-Nearest Neighbors (KNN)
KNN is a non-parametric set of rules that makes predictions based on the nearest friends within the function area. It is easy and powerful for each regression and class task.
Neural Networks
Neural networks, in particular deep learning of models, have received massive recognition in current years. They can gain an understanding of complicated styles and relationships in records via layers of interconnected nodes (neurons).
Challenges in Supervised Learning
While supervised gaining knowledge gives excellent benefits, it additionally poses a few challenges. Let’s discover some, not unusual place challenges:
Overfitting
Overfitting occurs when a supervised learning model becomes too complex and performs well on the training data but needs to generalize to new, unseen data. It happens when the model captures noise or irrelevant patterns in the training data. Regularisation techniques, such as L1 and L2, can help mitigate overfitting.
Underfitting
Underfitting happens when a supervised learning model needs to be more complex and capture the underlying patterns in the data. It leads to poor performance on both the training and test data. Underfitting can be addressed by increasing the model’s complexity or using more informative features.
Limited Training Data
Supervised learning heavily relies on labeled training data. However, obtaining high-quality labeled data can take time and effort. Limited training data can result in models that are prone to overfitting. Techniques like data augmentation, transfer learning, and active learning can be employed to address this challenge.
Feature Engineering
Feature engineering involves selecting, transforming, and creating relevant features to improve the performance of supervised learning models. It requires domain expertise and a deep understanding of the data. Feature engineering plays a crucial role in the success of SL algorithms.
Applications of Supervised Learning
SL finds applications in various domains. Here are some notable examples:
Image Classification: SL algorithms are used for tasks involving image categorization, including recognizing objects in pictures or recognizing handwritten digits.
Sentiment Analysis: SL helps analyze sentiment in text data, enabling sentiment analysis in social media posts, customer reviews, and feedback.
Credit Scoring: Banks and financial institutions use SL to assess creditworthiness and predict the risk of default by analyzing customer data.
Medical Diagnosis: SL algorithms assist in medical diagnosis by predicting diseases, analyzing medical images, and identifying patterns in patient data.
Recommendation Systems: E-commerce platforms and streaming services employ SL to personalize recommendations based on user preferences and behavior.
Fraud Detection: SL helps detect fraudulent activities in financial transactions by identifying patterns that indicate potential fraud.
Speech Recognition: Voice assistants and speech-to-text applications leverage SL algorithms to convert spoken language into text accurately.
Conclusion
Supervised gaining knowledge is an essential method in the system gaining knowledge, in which fashions analyze from categorized records to make predictions or classify new instances. It gives an extensive variety of algorithms, every one suitable for exceptional styles of problems. By know-how the standards and demanding situations of supervised gaining knowledge, we can leverage its strength in numerous real-global applications.